お断り
このネタは萌えるか萌えないかというネタです。なので、次のような人々はご遠慮ください。
- 「好き/嫌い」と「良い/悪い」「正しい/間違ってる」を区別できない人
- 萌えが気に食わないからと存在を消滅させたいような連中
- 人工知能が人間の領域を犯すとか言ってる人たち
人工知能を萌えさせてみよう
まぁ、人工知能ちうか、Deep Learningしてみようという話です。
ことの発端は Twitter。Twitter眺めてると、イラストを投稿してくれる絵師さんがけっこーいらっしゃいます。で、いいなぁこれ!ってなったら、保存しちゃうわけですが、TL見てないときにイラストが流れてたりすると、見逃してしまうわけです。
んじゃ、API 使って片っ端からダウンロードしたらどだろ?と
ダウンロードしてみました。
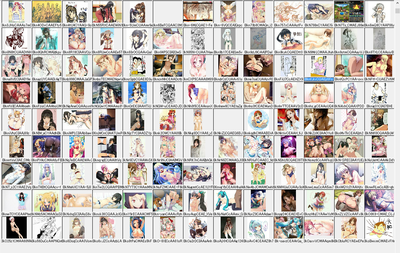 ん・・・・・・期待してたのと、ちょーっと違うかなぁ。期待してたイラストダウンロードされてはいるんですが、なんかそうじゃないのもけっこー混ざってる。実写写真とか、DVDとかの宣伝画像とかとかとか・・・・
ん・・・・・・期待してたのと、ちょーっと違うかなぁ。期待してたイラストダウンロードされてはいるんですが、なんかそうじゃないのもけっこー混ざってる。実写写真とか、DVDとかの宣伝画像とかとかとか・・・・
言い換えると、萌える画像と萌えない画像が混ざってる。
しかも、自動でダウンロード走らせてしまったもんだから、1000万個ちかくのファイルができてしまった。
こんなの、とーてー目視で振り分けなんぞやってられん!ということで、自動ふるい分けできんか??と考えたわけです。
これって、いってみりゃ画像認識なわけです。画像認識と言ったら Deep Learning!
さぁ、Deep Learning で萌える画像と萌えない画像を識別させてみよう!
よくあるDeep Learningは、「これは犬の写真です」「これは自動車の画像です」みたいな、物の形を識別するものがほとんどです。同じ仕組みで、「萌えるか萌えないか」すなわち、「好きか嫌いか」を識別できるのか??というのが新しい点かなと。
教師データの準備
まずは教師データの準備をば。
こればっかりは手動で振り分けるしかありません。手作業でこれはイイ!という画像を集めます。
萌える画像をごそっと。おおよそ3000枚
 次に萌えない画像もやっぱり3000枚ほど。あくまでも萌えない画像、すなわち、私が好きじゃない画像です。良いとか悪いとか、うまいとか下手とかじゃありません。念のため
次に萌えない画像もやっぱり3000枚ほど。あくまでも萌えない画像、すなわち、私が好きじゃない画像です。良いとか悪いとか、うまいとか下手とかじゃありません。念のため
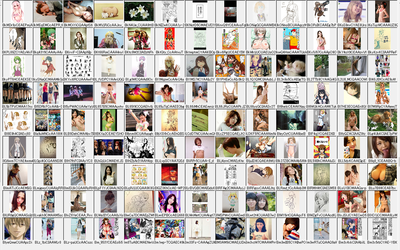 なお、実際には「うーん、これはどっちだ。判断できん」という保留も2000枚くらい出てきてます。これはDeep Learningの教師データには使いません。
なお、実際には「うーん、これはどっちだ。判断できん」という保留も2000枚くらい出てきてます。これはDeep Learningの教師データには使いません。
しっかしまぁ、どっちもエロ画像ばっかりやな(を
スクリプトをごりごり
学習させるためのデータが準備できたので、次はDeep Learningの実装。
import os
import numpy
import chainer
import chainer.functions as func
import chainer.optimizers
import random
import cv
import cv2
import io
import sys
import psycopg2
import pickle
import datetime
import locale
from PIL import Image
locale.setlocale(locale.LC_ALL , 'ja_JP.eucJP')
"""
model = pickle.load(open("model" , 'rb'))
"""
model = chainer.Chain (
conv1 = func.Convolution2D( 3, 32, 3, pad=1),
bn1 = func.BatchNormalization(32),
conv2 = func.Convolution2D(32, 32, 3, pad=1),
bn2 = func.BatchNormalization(32),
conv3 = func.Convolution2D(32, 32, 3, pad=1),
conv4 = func.Convolution2D(32, 32, 3, pad=1),
conv5 = func.Convolution2D(32, 32, 3, pad=1),
conv6 = func.Convolution2D(32, 32, 3, pad=1),
l1 = func.Linear(2048 , 512),
l2 = func.Linear(512 , 2))
def forward(x):
x = chainer.Variable(numpy.array(x, dtype=numpy.float32), volatile=False)
h = func.max_pooling_2d(func.relu(model.bn1(model.conv1(x))), 2)
h = func.max_pooling_2d(func.relu(model.bn2(model.conv2(h))), 2)
h = func.max_pooling_2d(func.relu(model.conv3(h)), 2)
h = func.max_pooling_2d(func.relu(model.conv4(h)), 2)
h = func.dropout(func.relu(model.l1(h)))
h = model.l2(h)
return h
optimizer = chainer.optimizers.Adam()
optimizer.setup(model)
def lean(pic , priority):
t = chainer.Variable(priority.astype(numpy.int32))
h = forward(pic)
optimizer.zero_grads()
d = func.softmax_cross_entropy(h, t)
d.backward()
optimizer.update()
if(h.data.argmax() == priority):
return True
else:
return False
def load_norm_img(imgpath):
img = Image.open(imgpath)
img = img.resize((128 , 128))
img = img.convert('RGB')
img = numpy.asarray(img)
img = img.transpose(2,0,1)
img = numpy.expand_dims(img, axis=0)
return img
def dir_lean(good_dir , bad_dir):
good_files = os.listdir(good_dir)
random.shuffle(good_files)
bad_files = os.listdir(bad_dir)
random.shuffle(bad_files)
num = min([len(good_files) , len(bad_files)])
hit = 0
count = 0
for i in range(0 , num):
count += 2
file = good_dir + "/" + good_files[i]
img = load_norm_img(file)
pri = numpy.array([0])
if(lean(img , pri)):
hit += 1
file = bad_dir + "/" + bad_files[i]
img = load_norm_img(file)
pri = numpy.array([1])
if(lean(img , pri)):
hit += 1
per = (hit * 100) / count
print(str(hit) + " / " + str(count)) + " ( " + str(per) + "% )"
for i in range(0 , 20):
print("Epoch " + str(i))
dir_lean("good" , "bad")
print(">>Update saved module<<")
pickle.dump(model , open("model" , 'wb') , -1)
こんなかんじ!
いやね、このBlogネタ書こうと思ったのは、このコードを書きたかったんですよ。このコード書くときに、Chainerってどーやって書くの?だれかサンプル公開してないの??って思って調べたんですが、全然出てこなかったんですよ。なもんで、じゃあ動くのできたらまるごと晒してみようかなと。
ただーし!このコード、拾い物の情報とか試行錯誤とかして書いたやつなので、本当に正しいの?と言われたら、さぁ?としか・・・・間違ってたら、だれかおせーて。
主要な部分を解説しましょう。
def load_norm_img(imgpath):
img = Image.open(imgpath)
img = img.resize((128 , 128))
img = img.convert('RGB')
img = numpy.asarray(img)
img = img.transpose(2,0,1)
img = numpy.expand_dims(img, axis=0)
return img
画像をファイルから読み込むサブルーチン。ファイルから読み込んで、128x128の解像度に縮小します。読み込んだ画像は当然二次元のデータですが、ニューラルネットワークに突っ込むには一次元配列にしないといけない。なので、そのための一次元化処理もこの中でやってます。
"""
model = pickle.load(open("model" , 'rb'))
"""
model = chainer.Chain (
conv1 = func.Convolution2D( 3, 32, 3, pad=1),
bn1 = func.BatchNormalization(32),
conv2 = func.Convolution2D(32, 32, 3, pad=1),
bn2 = func.BatchNormalization(32),
conv3 = func.Convolution2D(32, 32, 3, pad=1),
conv4 = func.Convolution2D(32, 32, 3, pad=1),
conv5 = func.Convolution2D(32, 32, 3, pad=1),
conv6 = func.Convolution2D(32, 32, 3, pad=1),
l1 = func.Linear(2048 , 512),
l2 = func.Linear(512 , 2))
次にモデル定義。これがニューラルネットワークの定義そのものです。畳み込み処理を2段通したあと、2048ノード、512ノード、2ノードの3層ネットワークです。
コメントアウトしてあるpickle.loadは、学習させたネットワークを保存しておいたものを読みだすときに使う処理。メインループでpickle.dump使ってmodel変数の中身、つまりネットワークをファイルに書き出してますが、これを読み込む場合はコメントアウトしたload処理を有効化して、変わりにmodel変数の定義をコメントアウトします。
def forward(x):
x = chainer.Variable(numpy.array(x, dtype=numpy.float32), volatile=False)
h = func.max_pooling_2d(func.relu(model.bn1(model.conv1(x))), 2)
h = func.max_pooling_2d(func.relu(model.bn2(model.conv2(h))), 2)
h = func.max_pooling_2d(func.relu(model.conv3(h)), 2)
h = func.max_pooling_2d(func.relu(model.conv4(h)), 2)
h = func.dropout(func.relu(model.l1(h)))
h = model.l2(h)
return h
つぎはネットワークの伝搬処理の実装部。ニューラルネットワークの第一層から第二層への伝搬はRelu関数とDropout関数を通して、第二層から第三層へは関数なし、つまりは線形関数で伝搬します。
def lean(pic , priority):
t = chainer.Variable(priority.astype(numpy.int32))
h = forward(pic)
optimizer.zero_grads()
d = func.softmax_cross_entropy(h, t)
d.backward()
optimizer.update()
if(h.data.argmax() == priority):
return True
else:
return False
最後に学習処理の本体。forwardで順方向伝搬をしたあと、伝搬結果を評価して、逆伝搬して、モデルをアップデートする。という処理をそのまんま流してます。
この関数と、forwad() 関数の中でVariable()関数を読んでますが、どうやらChainerで使う変数次元に合わせる関数のようで、お約束的に使うっぽいです。
さて結果は
教師データもそろった。処理系もできた。さぁ学習しましょう。
スクリプト内でパーセント値をprintしてる部分がありますが、画像を準に学習する際に、順伝搬させてその結果が期待している判定に一致した率を表示してます。
エポックが進むに従い、この割合が上がっていくことを期待して眺めるわけですが、なんと20から30エポックくらいで90%程度に達して、それ以上は上がらなくなりました。9割正しく判定できたら、まぁ十分じゃね??
というわけで、自動判定をしてみます!
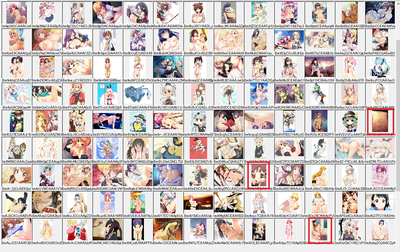
まずは萌えると判定された画像
 次に、萌えないと判定された画像
次に、萌えないと判定された画像
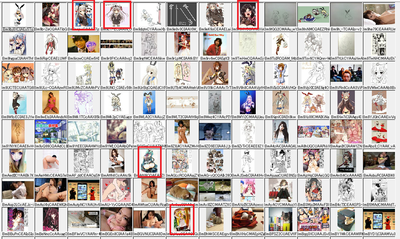 赤四角で囲ったのが判定ミスしてるものです。
赤四角で囲ったのが判定ミスしてるものです。
完璧とは言えないけど、まずまず十分に使い物になるレベルじゃね?
どっちにしたところで、エロ画像ばっかりやんけ!っていうのはおいておいて
 白飛びしてて見にくいですけど、右手に伸びてる青っぽいのが通した針金です。
白飛びしてて見にくいですけど、右手に伸びてる青っぽいのが通した針金です。 システム用の正、副に加えて、エアコンとか用の予備で3系統引き込んでます。さらにケーブルを通しましょう。
システム用の正、副に加えて、エアコンとか用の予備で3系統引き込んでます。さらにケーブルを通しましょう。 手前の灰色が先に通した電源。オレンジ色のが光ファイバーケーブル。黒いのがテレビアンテナ用の同軸線です。なお、この光ファイバーケーブル、ヤフオクで買った代物なんですが、500フィートのリールが3個で1万円という代物。この工事が終わってもまだ1本目のリールを使い切ってません。残ってるケーブル、何に使おう・・・・?
手前の灰色が先に通した電源。オレンジ色のが光ファイバーケーブル。黒いのがテレビアンテナ用の同軸線です。なお、この光ファイバーケーブル、ヤフオクで買った代物なんですが、500フィートのリールが3個で1万円という代物。この工事が終わってもまだ1本目のリールを使い切ってません。残ってるケーブル、何に使おう・・・・? んでまって・・・・・どーやらこのあたりから、父親がすごいやる気を出しまして。電源回りの内装がえらい本格的に。当初の計画では、ケーブルの先にOAタップ付けときゃいーだろ!って思ってたら、こんなんできてきました。
んでまって・・・・・どーやらこのあたりから、父親がすごいやる気を出しまして。電源回りの内装がえらい本格的に。当初の計画では、ケーブルの先にOAタップ付けときゃいーだろ!って思ってたら、こんなんできてきました。 鼠色の箱はブレーカ箱です。あと、室内コンセントはこんな感じ。
鼠色の箱はブレーカ箱です。あと、室内コンセントはこんな感じ。 冬はエアコンなしで行けるようにということで、家庭用の換気扇も設置。
冬はエアコンなしで行けるようにということで、家庭用の換気扇も設置。 それから、室内照明
それから、室内照明 この照明装置、オーム電機のLT-NLDM14D-HLっていう製品なんですが、いかにも!!っていう感じのLED照明。最近のデータセンターって、照明がLEDなのがほとんどなんですが、この照明で照らすと、いかにもデータセンターって雰囲気になります。(個人の感想であって効果をうんうんかんぬん)
この照明装置、オーム電機のLT-NLDM14D-HLっていう製品なんですが、いかにも!!っていう感じのLED照明。最近のデータセンターって、照明がLEDなのがほとんどなんですが、この照明で照らすと、いかにもデータセンターって雰囲気になります。(個人の感想であって効果をうんうんかんぬん) なお、エアコンはさすがに自前で工事は難しいので、電気屋さんにお願いする予定です。
なお、エアコンはさすがに自前で工事は難しいので、電気屋さんにお願いする予定です。